Classifying data is a common task in machine learning. Suppose some given data points each belong to one of two classes, and the goal is to decide which class a new data point will be in. In the case of support vector machines, a data point is viewed as a p-dimensional vector (a list of p numbers), and we want to know whether we can separate such points with a (p-1)-dimensional hyperplane. This is called a linear classifier.
There are many hyperplanes that might classify the data. One reasonable choice as the best hyperplane is the one that represents the largest separation, or margin, between the two classes. So we choose the hyperplane so that the distance from it to the nearest data point on each side is maximized.
If such a hyperplane exists, it is known as the maximum-margin hyperplane and the linear classifier it defines is known as a maximum margin classifier; or equivalently, the perceptron of optimal stability.
Usages
- Classification
- Regression
Pros
- Accuracy
- Works well on smaller cleaner datasets
- It can be more efficient because it uses a subset of training points
Cons
- Isn’t suited to larger datasets as the training time with SVMs can be high
- Less effective on noisier datasets with overlapping classes
Maximum Margin
Refer to this lecture by MIT OCW
# Decision rule
w.u + b >= 0 # Then Positive
# Constraints
w.x+ + b >= 1
w.x- + b <= -1
y (w.x + b) >= 1
y (w.x + b) - 1 == 0 # for gutter
# Width
(x+ - x-) . (w/|w|) = 1-b + 1+ b / |w| = 2/|w|
# Min (|w|) - min(1/2 |w|2)
# Minimization expression only depends on (xi.xj)Kernel Trick
In addition to performing linear classification, SVMs can efficiently perform a non-linear classification using what is called the kernel trick, implicitly mapping their inputs into high-dimensional feature spaces.
How to Select Support Vector Machine Kernels
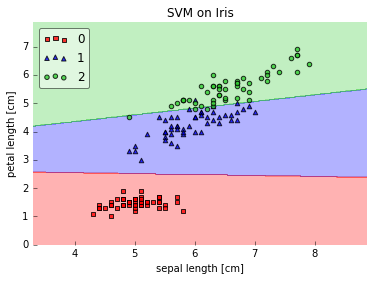
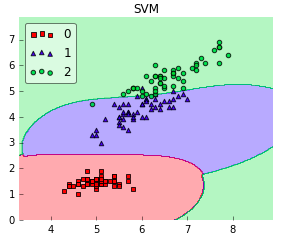
When to use linear:
When to use rbf:
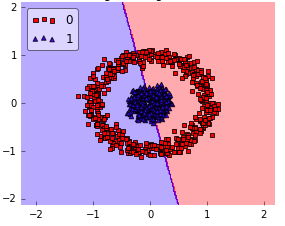
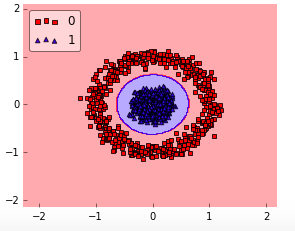
How rbf did this?
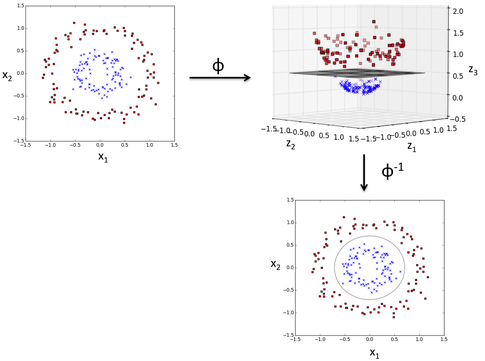
The RBF kernel SVM decision region is actually also a linear decision region. What RBF kernel SVM actually does is to create non-linear combinations of your features to uplift your samples onto a higher-dimensional feature space where you can use a linear decision boundary to separate your classes:
Python
#Import Library
from sklearn import svm
# Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object
model = svm.svc(kernel='linear', c=1, gamma=1)
# there is various option associated with it, like changing kernel, gamma and C value. Will discuss more # about it in next section.Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)